
朝日新聞のhtmlページの<head>~</head>内には、どのようなmeta(メタ)タグが書かれているのか、興味がありますよね。
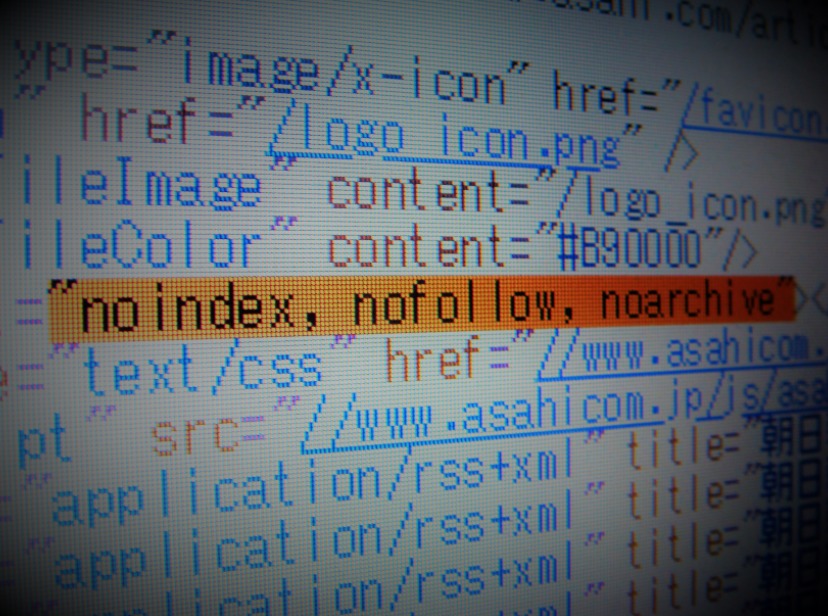
“noindex, nofollow, noarchive”の「検索避け」の他に、どのようなmetaタグを置いているのでしょうか。
気になって、いろいろ調べてみました。
noindexではない、朝日新聞が仕込んだもうひとつのmetaタグ
前回の記事、

のつづきです。
朝日新聞は「検索避け」について、子供の言い訳のようなわけのわからない説明をしているようです。産経新聞が報じています。
朝日新聞広報部は産経新聞の取材に対し、「記事を最終確認するため社内のみで閲覧できる状態で配信し、確認を終えてから検索可能な状態にした。その際に2本のタグ設定解除の作業が漏れてしまった」と説明し、24日までに設定を解除した。(産経新聞 2018.8.24)
おかしな言い訳です。
以下略ちゃんのブログでもそうですが、<head>~</head>内のmetaタグなどは、最初の設定が済めば、ひとつひとつの記事を書く時にいちいち触るような部分ではないのです。
まあ、朝日新聞の苦し紛れの言い訳はどうでもいいのですが、まだ問題は解決していません。
実は、問題なのは、朝日新聞が解除した”noindex, nofollow, noarchive”のmetaタグだけではなかったのです。
unavailable_after:2026/06/18: メタタグ
まずこちらの2018年8月18日の「訂正・おわび」のページ。

前回の記事では、このhtmlページの48行目にある
<meta name=”robots” content=”noindex, nofollow, noarchive“></meta>
を「検索避け」metaタグとして話題にしましたが、もうひとつ、気になるmetaタグを見つけました。
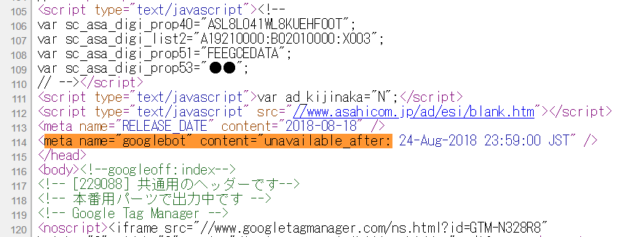
114行目にある
<meta name=”googlebot” content=“unavailable_after: 24-Aug-2018 23:59:00 JST“ />
です。
「robots」metaタグはすべての検索エンジンに有効ですが、「googlebot」metaタグは グーグル でのみ有効です。
unavailable_after:2026/06/18: はページのクロールとインデックス登録を中止する正確な日時を指定します。
参考 グーグルヘルプ
114行目の <meta name=”googlebot” content=”unavailable_after: 24-Aug-2018 23:59:00 JST” /> はどういう指図かというと、
- 2018年8月24日23時59分以降は、クローラー(検索ロボット)の巡回は中止してね。(二度とくるな)
- もしインデックス登録していたら、2018年8月24日23時59分に削除してね。(検索から削除されるのは翌日)
つまり、この8月18日の「訂正・おわび」のページに、グーグルのクローラーが巡回してくるのは24日まで限定であり、仮に検索に載ったとしても(載っていませんが)、8月24日23時59分に削除され、跡形もなく消えてしまうということになります。
こちらの「訂正・おわび」のページは、本当に、1週間限定なわけです。
朝日の一般記事の検索は約1年で消える
一般の記事ではどうなっているのでしょうか。
朝日新聞のこちらの2018年8月23日の記事でhtmlページを見てみます。

こららのページに「検索避け」の “noindex, nofollow, noarchive” はありませんが、
114行目には unavailable_after:2026/06/18: が入っています。
<meta name=”googlebot” content=”unavailable_after: 7-Sep-2019 23:12:01 JST” />
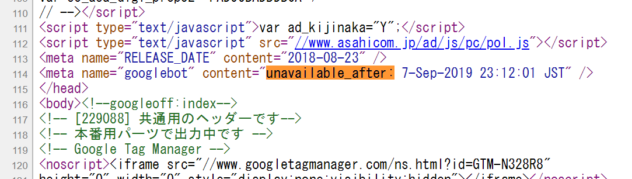
2019年9月7日23時12分01秒以降は、クローラー(検索ロボット)の巡回は中止、インデックス登録は削除して検索から除外するように、metaタグで指図をしています。
つまり、この記事は、現在は検索可能ですが、約1年後には、グーグルの検索ページから跡形もなく消えてしまうということです。
その後は、クローラーの巡回を拒否していますので、二度と検索に載ることはありません。
毎日新聞の場合
毎日新聞にも、同じ記事がありますので比較のために見てみます。

毎日新聞のこちらの記事のhtmlページには、“noindex, nofollow, noarchive” はありません。
unavailable_after:2026/06/18: もありませんでした。
産経新聞の場合
産経新聞に同じ記事があります。こちらも比較のために見てみます。

産経新聞のこちらの記事のhtmlページには、“noindex, nofollow, noarchive” はありません。
unavailable_after:2026/06/18: もありませんでした。
読売新聞の場合
読売新聞にも同じ記事があります。こちらも比較のために見てみます。

読売新聞のこちらの記事のhtmlページには、“noindex, nofollow, noarchive” はありません。
unavailable_after:2026/06/18: もありませんでした。
これら全国紙の同じニュースの記事において、朝日新聞だけが、「グーグルのクローラーの巡回」「グーグルのインデックス登録」の期限を「一般記事は約1年間」に限定するようmetaタグを入れていることがわかりました。
お詫び訂正記事ページについては、「インデックス登録は拒否」。「グーグルのクローラーの巡回」は、記事投稿後1週間限定のmetaタグを入れています。
グーグルのクローラーが巡回してこない限り、検索に載ることはありません。
noindexを外しただけでは、英語訳慰安婦吉田清治訂正記事は検索表示されない
ここで、気になるのは、朝日新聞の検索避け問題が発覚した最初の慰安婦問題の訂正記事です。
この訂正記事のhtmlページをもう一度見てみます。
現在は “noindex, nofollow, noarchive” が外されていますが、
111行目に(削除した分だけ移動した。本来は114行目)に、unavailable_after:2026/06/18: のmetaタグが残っています。
<meta name=”googlebot” content=”unavailable_after: 01-Dec-2100 20:14:00 JST” />
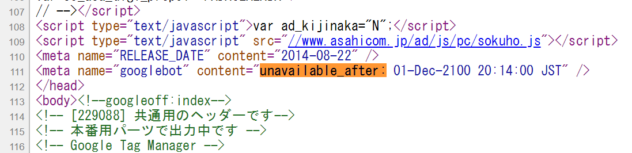
2100年12月1日20時14分以降は、インデックスを中止して、クローラーの巡回も止めるよう指図しているmetaタグが入っています。
ずいぶん先ですが、2100年には検索から消えてしまうことには、かわりありません。
この2100年という期限ですが、朝日新聞の他の一般記事は約1年後、「訂正・おわび」のページは1週間後なのですから、違和感があります。
おそらく、“noindex, nofollow, noarchive” を外すときに、ヤケクソで適当な未来の日付に書き換えたものと推測されます。
最初、ここに書き込まれていた日付は、おそらく2015年9月(約1年後)、または2014年8月28日(1週間後)だったのではないでしょうか。
そうであるならば、すでにその日付で、グーグルのクローラーの巡回は止まっていますので、今になって、“noindex, nofollow, noarchive” を外したとしても、クローラーは巡回してきません。
朝日新聞自身が、直接、グーグルにクローラーの巡回を要請しないかぎり、検索に載ることはないと思われます。
加筆
個別記事について、訂正・おわびがある場合は、後から該当の記事に加筆して「=訂正・おわびあり」というタイトルに変更しているようです。朝日新聞のサイトで「=訂正・おわびあり」で記事検索すると、約1年分の個別記事は見ることができました。
「<訂正して、おわびします>」で検索しても同じです。
「訂正・おわび」だけの記事の一覧ページは検索できないようになっていますが、個別の記事ページは、後から「訂正・おわび」を書き加えているようです。
ということは、英語訳の慰安婦の訂正記事ページは、「訂正・おわび」だけの記事ページ扱いだったということでしょうか?
例
ほとんどの人が読み終えて、拡散し終わった後に加筆して、どのくらいの人が気がつくかは不明です。
※わかりにくいですが、日にち別の「訂正・おわび」ページは検索避けされていますが、「訂正・おわび」のある個別記事は、個別に「訂正・おわび」が加筆されているということです。個別ページの検索避けはありません。すべての「訂正・おわび」が検索避けされているわけではないようです。
この記事の反応
当たりです! pic.twitter.com/K2OZvDeHd3
— ひまわり (@hinomoto_yuma) 2018年8月25日
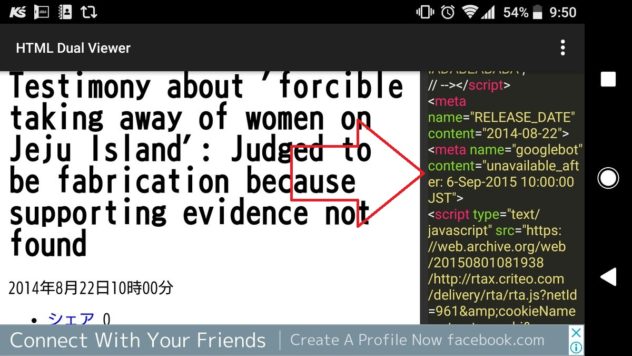
慰安婦問題の訂正記事の、訂正前の元のmetaタグは、
<meta name=”googlebot” content=”unavailable_after: 6-Sep-2015 10:00:00 JST” />
だったようです。
これですと2015年9月6日10時で、クローラーの巡回は止まっているようです。
関連記事


コメント
このgooglebotのタグですが、2100/12/1 20:14
の記載ですが、あまりにも不自然です
もしかして、この2100/12/1 20:14がタイムスタンプが正常に動作しない結果、早い時期に変わってしまうバグとかありえないでしょうか
ここまでいろいろ仕込んでいると、有り得そうな気がします
私もこれに類することをちょっと調べていました。
https://faq.digital.asahi.com/category/show/239?site_domain=default
に記事(一部を除く)を検索できる期間は1年、1年より前の記事検索は有料サービスを利用してもらいたいと、書いています。
過去の履歴を徹底的に調べたかったら web.archive.org に行って調べたいページのリンクアドレスを入れると、殆どの履歴が見れます! アサヒの2014年8月の問題の記事, noindex, noarchive とメタタグを忍ばせても米国の情報機関(?)にかかれば、見事に丸ごと保存しています! そのウェブページを開いて Ctrl+u でソースコードを出せば丸裸です。