朝日新聞が慰安婦訂正記事だけ「検索避け」していたことがわかりました。
吉田清治の慰安婦『奴隷狩り』は虚偽

![]()
朝日新聞の「吉田清治の慰安婦『奴隷狩り』」は、1982年以降繰り返し報じ、2014年8月5日に掲載した自社の慰安婦報道の「検証」記事でようやく虚偽と認めた架空の創作話です。
朝日新聞は、吉田清治氏(故人)を取り上げた記事16本を取り消しました。
吉田氏は、韓国・済州島で戦時中、女性を慰安婦にするため暴力を使って無理やり連れ出したと証言していました。記事取り消しは、吉田氏の証言を虚偽だと判断したためでした。
吉田氏の証言を虚偽だと判断したことを英語でも報道したのか?
この朝日新聞の「吉田清治の慰安婦『奴隷狩り』」の訂正記事を英語版でも報じているのかいないのかが話題になっていました。朝日新聞は報じていると主張していましたが、多くの人はきちんと報道していないのではないかと感じていました。
今回、有志の方の検証により、とんでもない新事実が明らかになりました。
朝日新聞は、英語版の「吉田清治の慰安婦『奴隷狩り』」の訂正記事を、グーグルの検索に掲載されないように工作していたのです。
ほとんどの人は、検索により記事を読みますので、検索に表示されないということは、英語圏ではほとんど誰も見ていないページということになります。
ツイッターなどの紹介により直接、記事を読む人というのは限られたわずかな人たちだけです。
meta(メタ)タグとは?
ブログをやっている人でないと馴染みが薄いかもしれませんが、meta(メタ)タグとは、htmlページのその文書に関する情報(メタデータ)を指定するものです。meta(メタ)データとは、『情報に関する情報』のことです。
つまり、そのWebページをどう見せるかという情報をmetaタグによって、検索エンジンや閲覧するブラウザなどに指示しています。
metaタグは、Googleクロームのデベロッパーツール(要素の検証)で、確認することができます。
朝日新聞の英語版訂正記事は検索に表示されない
32年間虚偽報道を行っていた朝日新聞が唯一掲載した海外向けの説明文というのが、2014年8月22日10時00分のこの記事です。

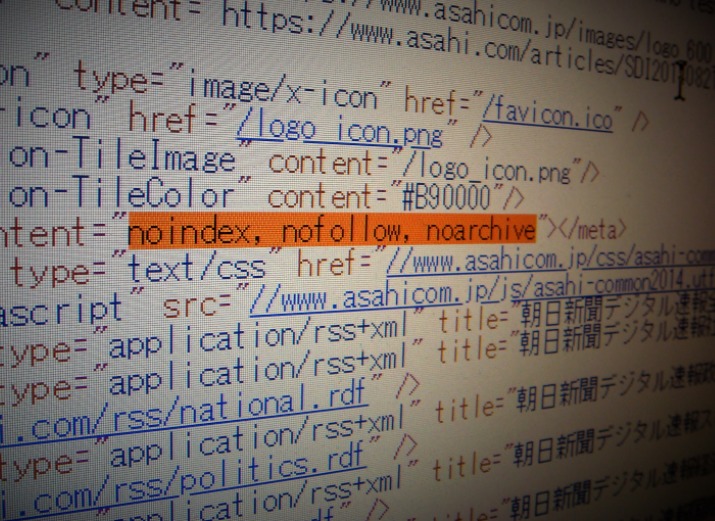
ところがこの記事のmetaタグを見てみると、次のようになっています。

<meta name=”robots” content=”noindex, nofollow, noarchive“></meta>
と書かれています。
グーグルの巡回してくるクローラー(ロボット)に、noindex, nofollow, noarchiveと指示しています。
「comfort women」「Seiji Yoshida」など、ページにあるどのような単語で検索しても、検索結果にこのページは掲載されていないことになります。
他の記事には検索避けのmetaタグはない
比較対象として、最近の記事「台湾に初の慰安婦像 前総統「正式な賠償と謝罪」訴える」のページも見てみましょう。


こちらの記事には、「noindex, nofollow, noarchive」はありません。
朝日新聞は「吉田清治の慰安婦『奴隷狩り』」の英語版訂正記事のみ、誰も見に来ないように、特別なmetaタグを入れているようです。
noindexタグとは?
noindex は、そのページを検索エンジンにインデックスさせないために使います。正確にいうと、インデックスはされるのですが、検索結果として表示されなくなります。
よくある使い方としては、コピーコンテンツ、重複ページ、エラーページなど、低品質でグーグルから評価を下げられそうなページに使います。
nofollowタグとは?
nofollowは、グーグルのクローラーがそのページにあるリンクをたどることができなくなります。
よくある使い方としては、低品質な評価の場合、そのままリンク先に影響を与えないようにする目的で使います。
noarchiveタグとは?
noarchiveは、ページをキャッシュされたくない時に使います。
グーグルはクローラーが巡回したときにキャッシュ(一時的な記憶ファイル)を作っており、オリジナルページが削除、非公開にされても、検索ページからキャッシュを見ることができます。
これを禁止することができます。ネット上に記録を残したくない時に使います。
※注 記事中では英語版と書きましたが、検索避けしているこの朝日新聞デジタルのページは、英語版ではなく、日本語版の英語訳ページのようです。


コメント
検索エンジンが使えないとすると、朝日の記事のホームページの直リンクを張ったホームページを新たに作って、それを検索させなければ、一般人は見つけられないでしょうね。サイトマップ見てもよくわからないし。
本件、ネットで指摘されて拡散してから、該当のmetaタグをこっそり削除しているようです。
朝日新聞はどこまで姑息なんでしょうか。
お詫びと訂正記事全てにタグが仕込まれていることからして、特権階級気取りなのは間違いない。
英語版のサイトにある謝罪文pdfは題名からして慰安婦や吉田証言に触れていないし、炎上中の記事はそもそも日本語版サイトに掲載されていて英語圏の人には…
やっぱ朝日は糞。