訂正記事は「検索避け」あり、修正した元記事は「検索避け」なし
「検索避け」をされている「訂正ページ」と、「検索避け」をされていない「訂正したページ」がわかりにくいので、実例を上げて整理してみます。
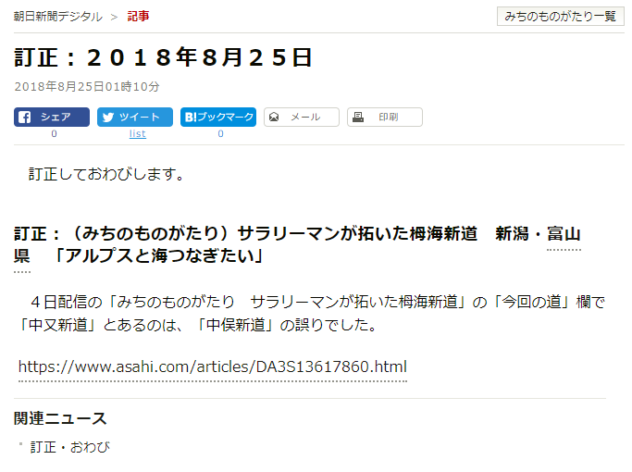
①朝日新聞が2018年8月25日に訂正記事を投稿しました。
②8月25日に、訂正したのは、8月4日の記事です。
断崖に日本海の荒波が打ち寄せる天嶮(てんけん)・親不知(新潟県糸魚川市)。ここから北アルプス北端の朝日岳(2418メー…

「中又新道」とあるのは、「中俣新道」の誤りでした。
という漢字の間違いです。これを3週間放置した後に訂正したわけです。
2018年8月25日の訂正記事①のページに投稿するとともに、該当の8月4日の記事②の「中又新道」を「中俣新道」に直し、文末に
<訂正して、おわびします>
▼4日付6、7面「みちのものがたり サラリーマンが拓いた栂海新道」の「今回の道」欄で「中又新道」とあるのは、「中俣新道」の誤りでした。
を加筆しています。
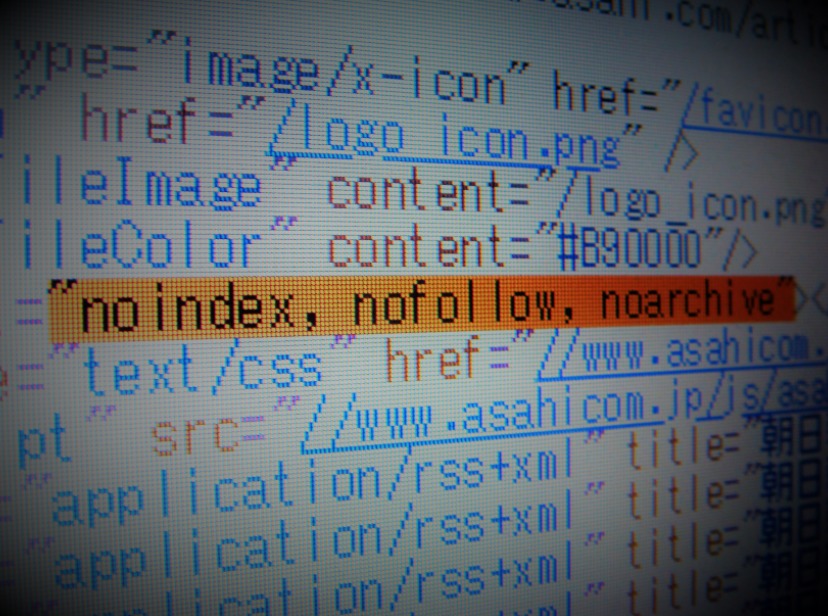
①の2018年8月25日に訂正記事のhtmlページには、48行目に
<meta name=”robots” content=”noindex, nofollow, noarchive“></meta>
115行目に
<meta name=”googlebot” content=”unavailable_after: 31-Aug-2018 23:59:00 JST” />
が入っています。
②の訂正対象の8月4日の記事には、“noindex, nofollow, noarchive” のmetaタグはありません。
114行目に
<meta name=”googlebot” content=”unavailable_after: 19-Aug-2019 03:30:00 JST” />
が入っています。
文章としては重複しているので、①の訂正記事の方に “noindex, nofollow, noarchive” のmetaタグを入れているという解釈ができないこともないのですが、①の訂正記事は、「8月25日に4日の記事の訂正が見つかりました」という新しい記事ですので、こちらの方に「検索避け」のmetaタグを入れるのは、やはりおかしいと思います。
②の8月4日の記事では、25日に修正されたことがわかりません。それに25日に書き直しても、ほとんど誰も気が付かないでしょうし、ほとんど誰も見に行かないですよ。